
Kompiuterinių tinklų priežiūra yra visapusiškas procesas, apimantis reguliarų stebėjimą, techninę bei programinę įrangos profilaktiką ir optimizavimą, kuris užtikrina sklandų ir saugų tinklo veikimą. Šiuolaikinėse įmonėse, kur verslo procesai stipriai priklauso nuo skaitmeninių sistemų, netinkama tinklų priežiūra gali sukelti brangiai kainuojančius prastovų laikotarpius, duomenų praradimą ar net saugumo pažeidimus. Vidutinio dydžio įmonė gali patirti tūkstančius eurų nuostolių per valandą dėl nenumatytų tinklo sutrikimų. Šiame straipsnyje pateikiame praktinį tinklo priežiūros planavimo modelį, įrankių rekomendacijas bei geriausias praktikas, kurios padės užtikrinti jūsų tinklo infrastruktūros patikimumą ir efektyvumą.
Kodėl svarbi proaktyvi priežiūra
Tinklo priežiūrą galima skirstyti į dvi pagrindines kategorijas: reaktyvią (sprendžiančią jau iškilusias problemas) ir prevencinę (užkertančią kelią problemoms). Nors daugelis organizacijų vis dar remiasi reaktyviuoju modeliu, proaktyvi tinklo priežiūra siūlo žymiai didesnę investicijų grąžą.
Ji padeda sumažinti neplanuotų prastovų skaičių, prailgina techninės įrangos tarnavimo laiką, gerina vartotojų pasitenkinimą bei sumažina bendrąsias IT valdymo išlaidas.
Prevencinė ir reaktyvinė priežiūra – lyginamasis pavyzdys
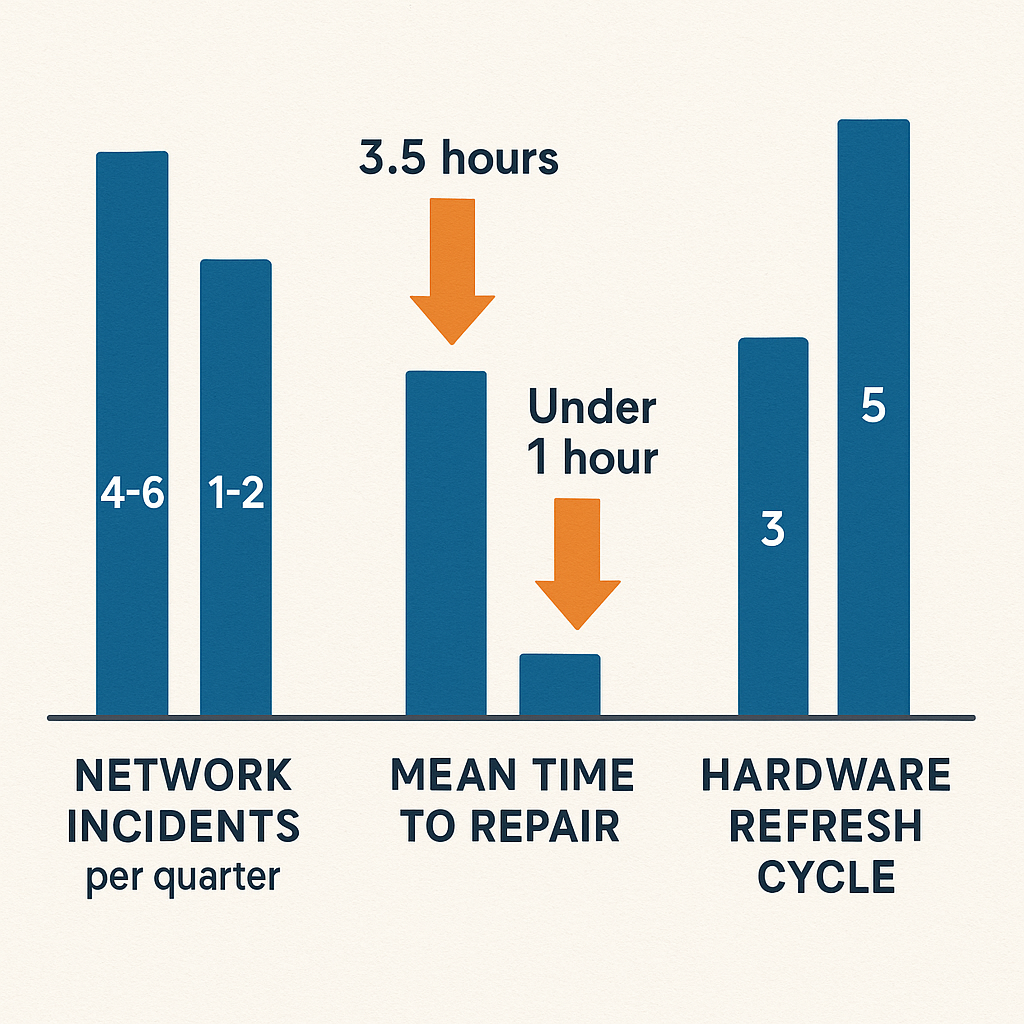
Analizuojant 50 darbuotojų turinčios įmonės atvejį, kuri perėjo nuo reaktyvios prie planinės tinklo priežiūros, pastebėti reikšmingi pokyčiai. Prieš įdiegiant proaktyvią strategiją, įmonė vidutiniškai patirdavo 4-6 neplanuotus tinklo sutrikimus per ketvirtį, o vidutinis gedimo šalinimo laikas (MTTR) siekė 3,5 valandas. Įdiegus reguliarius tinklo auditus, stebėsenos sistemas ir automatizuotą įrangos atnaujinimą, sutrikimų skaičius sumažėjo iki 1-2 per ketvirtį, o MTTR sutrumpėjo iki mažiau nei 60 minučių. Be to, infrastruktūros atnaujinimo ciklą pavyko prailginti nuo 3 iki 5 metų dėl geresnės įrangos priežiūros.
Pagrindiniai priežiūros plano komponentai
Veiksmingas kompiuterinių tinklų priežiūros planas remiasi penkiais esminiais ramsčiais: dokumentacija, grafiku, stebėjimu, testavimu ir ataskaitomis.
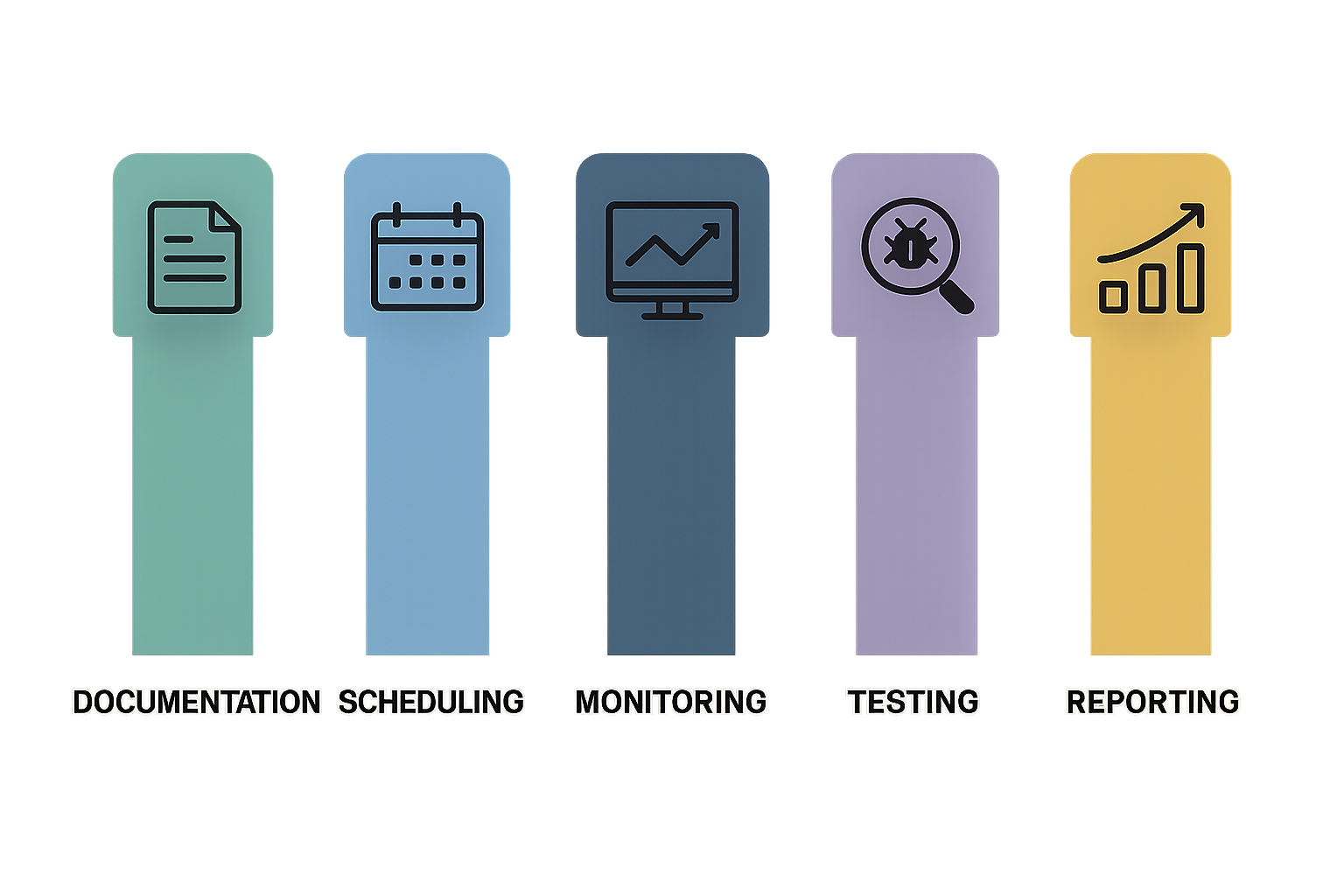
Šie komponentai sudaro visapusišką sistemą, užtikrinančią tinklo stabilumą ir saugumą.
- Tinklo dokumentacija – išsamūs tinklo topologijos žemėlapiai, IP adresų planai, konfigūracijos failai ir įrangos inventorius.
- Techninio aptarnavimo tvarkaraštis – reguliarūs planiniai patikrinimai, programinės įrangos atnaujinimai ir saugumo auditai.
- Nuolatinis stebėjimas – tinklo našumo, įrangos būklės ir anomalijų sekimas.
- Testavimo protokolai – apkrovos bandymai, atsarginių planų tikrinimas ir saugumo spragų vertinimas.
- Atskaitomybės sistema – incidentų registravimas, sprendimų istorija ir tendencijų analizė.
Būtini įrankiai ir programinė įranga priežiūrai
Efektyviai tinklų priežiūrai reikalingi specializuoti įrankiai, kurie padeda automatizuoti stebėjimą, aptikti problemas, valdyti atnaujinimus ir užtikrinti saugumą.

Pagrindinės įrankių kategorijos apima stebėsenos sistemas, audito programas, atnaujinimų valdymo platformas ir saugumo tikrinimo priemones.
- Tinklo stebėsenos įrankiai: Nagios, Zabbix, PRTG Network Monitor, SolarWinds
- Saugumo įrankiai: Nessus, OpenVAS, Wireshark, Snort
- Konfigūracijos valdymo įrankiai: Ansible, Puppet, SolarWinds NCM
- Tinklo veikimo analizės įrankiai: Netflow Analyzer, ntopng, Paessler PRTG
Atviro kodo ir komercinės stebėsenos įrankių palyginimas
Rinkoje egzistuoja daug skirtingų sprendimų, todėl svarbu pasirinkti labiausiai jūsų poreikius atitinkančius įrankius:
| Kriterijus | Atviro kodo (Nagios/Zabbix) | Komerciniai (SolarWinds/PRTG) |
|---|---|---|
| Pradinės išlaidos | Minimalios (nemokama programinė įranga) | Aukštos (licencijų kainos) |
| Pritaikymo lankstumas | Labai didelis, bet reikalauja techninių žinių | Vidutinis, ribotas derinimas |
| Vartotojo sąsaja | Paprastesnė, mažiau intuityvi | Profesionalesnė, labiau patogi vartotojui |
| Palaikymas | Bendruomenės forumų pagalba | Profesionalus techninis palaikymas |
| Mastelio keitimas | Sudėtingesnė konfigūracija didelėse aplinkose | Paprastesnis valdymas didelėse aplinkose |
Saugios ir plečiamos priežiūros geriausia praktika
Sistemingas požiūris į tinklų saugumą ir gebėjimas prisitaikyti prie augančių poreikių yra esminiai aspektai kuriant patvarią tinklo priežiūros strategiją. Šiuolaikiniai saugumo standartai ir tinklo segmentavimas padeda užtikrinti nenutrūkstamą veikimą.
- Tinklo segmentavimas – įdiekite VLAN ir segmentavimo praktikas, kad apribotumėte potencialių incidentų poveikį
- Prieigos kontrolės sąrašai (ACL) – naudokite išsamius ACL srauto filtravimui ir saugumui užtikrinimui
- Saugumo incidentų valdymas – sukurkite aiškius protokolus incidentų atpažinimui ir reagavimui
- Duomenų šifravimas – užtikrinkite visų kritinių duomenų šifravimą persiuntimo ir saugojimo metu
Planuojant kompiuterinių tinklų priežiūrą, visada reikia laikytis principinio išbandymo metodo – pirma testuokite atnaujinimus ir konfigūracijos pakeitimus ne gamybinėje aplinkoje. Tai sumažina riziką ir užtikrina sklandų diegimo procesą.
Gedimų šalinimas ir dažniausiai iškylantys iššūkiai
Net ir taikant geriausias praktikas, kompiuterinių tinklų administratoriai susiduria su įvairiais iššūkiais. Efektyvus problemų sprendimas priklauso nuo sistemingo požiūrio ir tinkamų įrankių.
Dažniausiai pasitaikančios problemos:
- Nepastovus ryšys – gali būti susijęs su fiziniais jungtimis, maršrutizavimo problemomis arba elektromagnetiniais trukdžiais
- Lėtas tinklo veikimas – dažnai sukelia perkrova, netinkamai sukonfigūruotos QoS taisyklės arba senėjanti įranga
- DNS problemos – sukelia naršymo vėlavimus ir programų veikimo sutrikimus
- Saugumo incidentai – kenkėjiškos programos, įsilaužimai ar DDoS atakos
Sistemingo gedimų šalinimo metodas:
- Identifikuokite požymius ir apibrėžkite problemą
- Surinkite duomenis naudodami diagnostinius įrankius (ping, traceroute, tcpdump, Wireshark)
- Išanalizuokite surinktą informaciją ir nustatykite galimas priežastis
- Pritaikykite sprendimą ir patikrinkite rezultatą
- Dokumentuokite problemą ir jos sprendimą
Štai paprastas paketų stebėjimo pavyzdys naudojant tcpdump įrankį, norint aptikti tinklo lėtumo problemas:
tcpdump -i eth0 -nn port 80 -s 0 -w web_traffic.pcap
Šio įrašyto duomenų failo analizė su Wireshark įrankiu gali padėti nustatyti paketų vėlavimą, praradimą ar kitas anomalijas, kurios sukelia tinklo veikimo problemas.
Apibendrinimas
Efektyvi kompiuterinių tinklų priežiūra reikalauja sistemingo požiūrio, apimančio tiek proaktyvią, tiek reaktyvią valdymo metodiką. Organizacijos, investuojančios į išsamų priežiūros planą, galingas stebėsenos priemones ir specialistų komandas, gali žymiai sumažinti nenumatytų prastovų riziką, pailginti įrangos tarnavimo laiką ir užtikrinti optimalų tinklo veikimą.
Pagrindiniai tinklų priežiūros elementai apima:
- Išsamią ir nuolat atnaujinamą dokumentaciją
- Reguliarią techninę priežiūrą ir atnaujinimų valdymą
- Nuolatinį veikimo stebėjimą ir analizę
- Daugiasluoksnį saugumo užtikrinimą
- Efektyvias gedimų šalinimo procedūras
Pritaikant šiame straipsnyje aprašytas praktikas, organizacijos gali sukurti stabilią ir saugią tinklo infrastruktūrą, kuri patikimai tarnaus verslo poreikiams ir suteiks konkurencinį pranašumą. Proaktyvi tinklo priežiūra – tai ne tik techninė būtinybė, bet ir strateginė investicija į įmonės skaitmeninę ateitį.
Dažniausiai užduodami klausimai (DUK)
Kas yra kompiuterinių tinklų priežiūra ir kodėl ji svarbi?
Kompiuterinių tinklų priežiūra – tai sisteminis procesas, apimantis reguliarų stebėjimą, atnaujinimą ir optimizavimą tinklo infrastruktūros veikimui užtikrinti. Ji yra itin svarbi dėl trijų pagrindinių priežasčių: užtikrina maksimalų tinklo veikimo laiką, sustiprina saugumo apsaugą ir sumažina bendras IT eksploatacijos išlaidas.
Kaip dažnai reikėtų atlikti tinklo priežiūrą?
Tinklo priežiūros dažnumas priklauso nuo infrastruktūros dydžio ir kritinio pobūdžio, tačiau rekomenduojama laikytis tokio grafiko: savaitinis stebėjimas ir pagrindinių parametrų tikrinimas, mėnesinis programinės įrangos atnaujinimas ir pataisų diegimas, ketvirtinis išsamus saugumo ir veikimo auditas.
Kokie įrankiai geriausi tinklo stebėsenai?
Populiariausi ir daugiausiai funkcijų siūlantys tinklo stebėsenos įrankiai yra: Nagios (atviro kodo, labai lankstus), Zabbix (plačios galimybės ir grafinis vaizdavimas), PRTG Network Monitor (patogi vartotojo sąsaja ir platus jutiklių pasirinkimas), SolarWinds (įmonėms pritaikyti sprendimai) ir LibreNMS (nemokama ir lengvai įdiegiama alternatyva).
Kaip galiu automatizuoti prevencinės priežiūros užduotis?
Prevencinės priežiūros automatizavimą galima pasiekti naudojant skripto automatizavimą (Python, PowerShell, Bash), įdiegiant nuotolinės stebėsenos įrankius (RMM), konfigūruojant automatines tvarkaraščio sistemas (cron, Task Scheduler), naudojant konfigūracijos valdymo įrankius (Ansible, Puppet) ir nustatant automatinius įspėjimus kritiniams įvykiams.
Kokios didžiausios klaidos daromos tinklo priežiūroje?
Didžiausios tinklo priežiūros klaidos yra dokumentacijos nebuvimas arba jos neatnaujinimas, atsarginių kopijų nekūrimas prieš diegiant atnaujinimus, įspėjamųjų signalų ignoravimas, saugumo spragų taisymų atidėjimas ir sistemingos priežiūros strategijos nebuvimas. Šios klaidos gali sukelti ilgas prastovas ir reikšmingus duomenų praradimus.

 Nemokamas IT ūkio auditas.
Nemokamas IT ūkio auditas.



